

Home | Call for Papers | Submissions | Journal Info | Links |
Journal of the Slovene Association of LSP Teachers
ISSN: 1854-
Pedro A. Fuertes-
Pedagogical Application of Specialized Corpora in ESP Teaching: the case of the UVaSTECorpus
ABSTRACT
This article contributes to defining the concept of specialized corpora, reviews
the rationale for using them instead of general corpora in teaching activities, and
offers the state of art in both corpus-
Keywords: specialized corpora, ESP, lexical gender, classroom activities.
1. Introduction: Corpus Linguistics and the Study of the English Language
As a relatively new approach to language studies, corpus linguistics has witnessed
that the number and depth of many corpus approaches to the study of the English language
is constantly increasing. Since the 2000s, we have observed the development of a
complementary process aiming at building both giga-
A specialized corpus comprises representative oral and/or written texts which reflect the kind of language of a particular domain. Although there is no limit to the degree of specialization involved, specialized corpora tend to accord to a set of parameters which refer to genre, topic, size, text type, and language variety. Flowerdew (2004: 21) summarizes the parameters by which corpus linguists tend to define specialized corpora, with examples illustrating them (Table 1). She adds that although the parameters in Table 1 are presented as discrete categories, there is an overlap between some of them; for example, contextualization is also an aspect of genre.
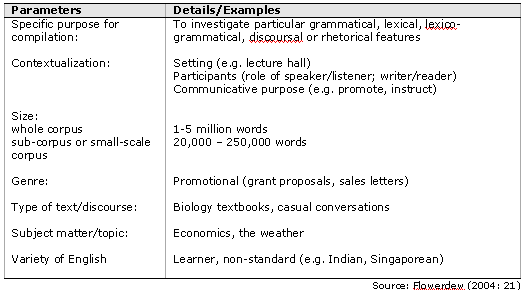
Table 1: Parameters for defining corpora as specialized
Seven arguments are usually indicated for explaining why general corpora may be unsuitable
for investigating specialized language. First, general-
After reviewing current work with specialized corpora, the article describes some
key features of the University of Valladolid Scientific and Technical Written English
Corpus (UVaSTECorpus). The description illustrates how a localized, in-
2. Corpus Studies of Academic and Professional English
Recent research pays attention to the ethnographic dimension and extra-
2.1. Teaching and research activities with in-
By localized in-
a) corpus work that reports practical comments on the pros and cons of using corpora
in the classroom, paying attention to working with concordances (Gavioli, 2005),
or integrating the lexical approach with data-
b) corpus work that compares the language produced by native and non-
c) corpus work that investigates the discursive features of a discipline or group of disciplines which provides information on how to organize the teaching tasks. Some common topics are politeness, mood and modality, personal reference, metadiscourse, hedging devices, phraseological patterning and interactive features such as personal deictics, markers, and imprecise quantifiers (Charles, 2006; Flowerdew & Wan, 2006; Harwood, 2005; Hyland & Tse, 2005; Webber, 2005). Flowerdew & Wan (2006: 150), for example, indicate that tax accountants use very formulaic and standardized templates, which must be incorporated into the teaching of professional writing.
d) corpus work that focuses on the rhetorical structure of genres such as ‘e-
2.2. Teaching and research activities with open access corpora
By open access corpora I refer to some corpora which have been compiled by one or more institutions with the aim of making them available to the research community which can engage into two main complimentary tasks: (i) to replicate previous analyzes in order to falsify the hypothesis being tested; (ii) to broaden the scope of research concerned with both drawing pedagogical applications and allowing the grammar of ESP to emerge. Below, I will comment on some recent findings drawn from open access corpora:
a) The Michigan Corpus of Academic Spoken English (MICASE) is a spoken language corpus
of approximately 1.9 million words of contemporary university speech recorded at
the University of Michigan. Using this corpus, Simpson (2004), for example, identified
a list of all three-
b) The TOEFL 2000 Spoken and Written Academic Language (T2K-
c) The British Academic Spoken English (BASE) Corpus and the British Academic Written
English Corpus (BAWE) Corpus were developed under the leadership of Hillary Nesi.
They allow investigation on the following: frequency and range of academic lexis;
the meaning and use of individual words and multi-
d) The Cambridge and Nottingham Corpus of Business English (CANBEC) is a collection of spoken business English recorded in companies of all sizes, from big multinational companies to small partnerships. Formal and informal meetings, presentations, conversations on the phone, over lunch etc. were recorded, and typed into the computer for analysis by authors and editors. McCarthy & Handford (2004: 187), for example, summarize some pedagogical implications regarding spoken business English (SBE):
(i) a good deal of the linguistic content of SBE is shared with casual conversation.
Hence, a comprehensive SBE pedagogy would prioritize awareness of areas such as personal
deixis, face-
(ii) business English materials must also focus on abstract states and qualities,
such as politeness. The evidence shows that mitigating face-
(iii) skill in hedging and use of purposive vagueness must be stressed;
(iv) close observation of the achievement of speech acts such as requests and directives
while maintaining comity in SBE contexts is a useful awareness-
(v) although many users of SBE will be using it as a lingua franca in non-
(vi) as more spoken business corpora become available, data-
3. Compiling your In-
Although we are working for converting the University of Valladolid Scientific and
Technical Written English Corpus (UVaSTECorpus) in an open access corpus, accessible
to the research community through the Internet, at the moment it is a localized,
in-
This corpus stands at our original target of 3,000,000 words of scientific and technical
English (my emphasis). It was designed by Fuertes Olivera (2007b), collected at the
University of Valladolid by José María Rodrigues and Pedro A. Fuertes-
Assuming that a corpus should be compiled falling back on non-
The documents are restricted to the last 25 years, and are the product of three types
of users: native researchers; non-
The former comprise texts produced by researchers in different fields published in
peer-
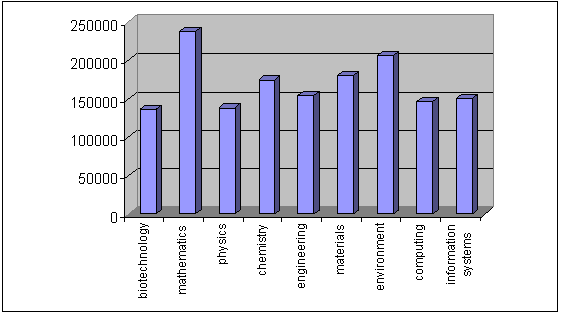
Figure 1: Number of words per domain of the research articles included in the sub-
The latter consists of official documents produced by government bodies and professional
societies. These were grouped into two main categories: informational reports; instructional
documents. Informational reports are the work of national and/or international committees
(for example, the National Science and Technology Committee) and aim at reviewing
national and/or international policies on science and technology (for example, national
priorities in science and technology policy), or informing on research priorities,
or other science and technology issues (for example, the science of climate change:
adapt, mitigate or ignore?). Instructional documents are also produced by official
bodies aiming at giving instructions on different aspects: ‘talks’ (typically delivered
by politicians at the opening and/or closing sessions of Science and Technology-
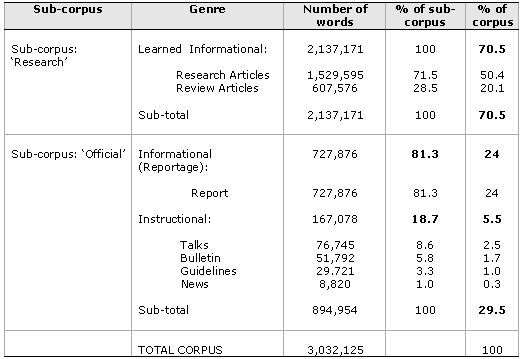
Table 2. Documents in the UVaSTECorpus
4. Working with the UVaSTECorpus
In terms of methodology, corpus linguists share some general criteria about what
corpus-
· Students are informed on the importance of the “idiom principle” (Sinclair 1991): many words have a tendency to occur together or in each other vicinity, “unusuality” (Partington 1998) and creativity go hand in hand, and collocations, colligations, semantic preferences, and semantic prosodies (Sinclair 1996) are part and parcel of the English language. For example, bridge gaps, found in both the WebCorpus and the UVaSTECorpus, derives from bridge the gap:
“NSF co-
(UVaSTECorpus: Official)
· Students are explained that words form conceptualizations of reality which define the culture of a discourse community. For example, the noun bucket in computing refers to a storage area containing data for an application (example 2), whereas the expression “bucket chemistry”, also found in the corpus, refers to traditional experiments in chemistry (example 3):
“The naïve comparison algorithm is 0n.29, but this is easily improved by hashing lines into B buckets, and then comparing only lines in the same bucket.”
(UVaSTECorpus: Research)
“Branches around the country run bucket chemistry competitions for secondary schools. The competition introduces the idea of producing chemicals in large amounts to children.”
(UVaSTECorpus: Official)
· Students are guided to read concordances. In this respect, it is useful for them
to know “that they do not have to read the entire lines, but simply scroll the search
word, looking, for instance, for adjectives and verbs preceding it” (Gavioli 2005:
74). Following Gavioli (2005: 75-
1. Read the concordance vertically, following the search word column and the word to the left of it. Underline the words to the left of, say, Ms in the text.
2. Do these words give you an idea of what Ms is? Discuss your idea with your colleagues and teacher.
3. The following is the information on Ms provided in the Cobuild Dictionary ; Is it helpful in clarifying the meaning of this word?:
i. Ms is used, especially in written English, before a woman’s name when you are speaking to her or referring to her.
ii. If you use Ms, you are not specifying if the woman is married or not.
4. On the basis of the dictionary information, look at the concordance again and identify examples illustrating information i. or ii. next to the lines you selected.
5. Look at the example extracted from the dictionary: does it illustrate information i. or ii. (or both) clearly?:
“I wrote to Ms Walters and gave my opinion.”
6. Select some examples in the concordance of Ms which you think illustrate information i. or ii. or both clearly. You can widen the text of each line to get more context.
7. Which information is more frequent in the concordance of Ms, i. or ii.? Why, do you think?
· Students are explained the meaning of grammatical terms. Biber et al. (1999), and
Biber (2006) use the term grammatical term as a general covert term for anything
that recurs in texts that can be given a linguistic description, and explain them
in terms of linguistic theories. It is claimed that much of the variation among features
is highly systematic: speakers of a language make choices in morphology, lexicon,
and grammar depending on a number of linguistic and non-
One issue subject to much debate is the use of “generic man”, as many English grammars,
mainly prescriptive ones, usually state that masculine terms such as “generic man”
can often be used as duals to refer to both women and men. Advocates of ‘non-
![]()
Table 3. Occurrences of ‘generic man’ and ‘person’ in the UVaSTECorpus. % per 100.000 words
Table 3 shows that advocates of non-
5. Conclusion
This article comments on some pedagogical applications of small specialized corpora
in ESP teaching activities. After reviewing current work with both in-
1 For example, the English Gigaword Corpus, produced by the Linguistic Data consortium. See: http://www.ldc.upenn.edu/Catalog/CatalogEntry.jsp?catalogId=LDC2003T05.
2 See: http://quod.lib.umich.edu/m/micase/.
3 http://www.rdg.ac.uk/slals/base/.
4 Around 80% or more of scientific and technical research is published in English (cf. Crystal 1997).
5 including ‘profiles’, ‘PhD summaries, letters, discussions, notes, etc.
References
Biber, D. (2006). University Language. A Corpus-
Biber, D., S. Johansson, G. Leech, S. Conrad & E. Finegan (1999). Longman Grammar of Spoken and Written English. London: Longman.
Biber, D., S. Conrad, R. Reppen, P. Byrd, M. Helt, V. Clark, V. Cortes, E. Csomay, & A. Urzua (2004). Representing Language Use in the University. Analysis of the TOEFL 2000 Spoken and Written Academic Language Corpus. Princeton, NJ: ETS.
Bowker, L. (2001). “Terminology and gender sensitivity: a corpus-
Bowles, H. (2006). Bridging the gap between conversation analysis and ESP – an applied
study of the opening sequences of NS and NNS service telephone calls. English for
Specific Purposes 25, 332-
Burnard, L. (2002). “A retrospective look at the British National Corpus”. In B.
Kettemann & G. Marko (eds), Language and Computers: Studies in Practical Linguistics,
51-
Cameron, D. (1996). “The language gender interface: challenging co-
Charles, M. (2006). “Phraseological patterns in reporting clauses used in citation:
a corpus-
Coates, J. (ed.) (1998). Language and Gender. A Reader. Oxford: Blackwell.
Crystal, D. (1997). English as a Global Language. Cambridge: Cambridge University Press.
Donohue, J. P. (2006). How to support a one-
Flowerdew, J. and A. Wan (2006): “Genre analysis of tax computation letters: How
and why tax accountants write the way they do”. English for Specific Purposes 25:
133-
Flowerdew, L. (2004). The argument for using English specialized corpora to understand
academic and professional language. In U. Connor & T. A. Upton (Eds.), Discourse
in the Professions. Perspectives from Corpus Linguistics, 11-
Flowerdew, L. (2005). An integration of corpus-
Fuertes-
Fuertes Olivera, P. A. (2007b). “El lenguaje de la ciencia y la tecnología”. In Enrique
Alcaraz Varó et al. (eds.), Las lenguas profesionales y académicas, 205-
Fuertes Olivera, P. A., M. Velasco Sacristán, M. & E. Samaniego Fernández (2003).
“Gender sensitivity in specialized communication: a preliminary corpus-
Gabrielatos, C. & T. McEnery (2005). “Epistemic modality in MA dissertations”. In
P. A. Fuertes Olivera (ed.), Lengua y sociedad. Investigaciones recientes en lingüística
aplicada, 311-
Gavioli, L. (2005). Exploring Corpora for ESP Learning. Amsterdam/Philadelphia: John Benjamins.
Gimenez, J. (2006). Embedded business emails: Meeting new demands in international
business communication. English for Specific Purposes 25: 154-
Gries, S. Th. (2006). “Introduction”. In S. Th. Gries & A. Stefanowitsch (eds.),
Corpora in Cognitive Linguistics. Corpora-
Harwood, N. (2005). ‘I hoped to counteract the memory problem, but I made no impact
whatsoever’: discussing methods in computing science using I. English for Specific
Purposes 24: 243-
Hyland, K. & P. Tse (2005). Hooking the reader: a corpus study of evaluative that
in abstracts. English for Specific Purposes 24: 123-
Kanoksilapatham, B. (2005). Rhetorical structure of biochemistry research articles.
English for Specific Purposes 24: 269-
Kwan, B. S.C. (2006). The schematic structure of literature reviews in doctoral theses
of applied linguistics. English for Specific Purposes 25: 30-
Lee, D. (2001). “Genres, registers, text types, domains and styles: clarifying the
concepts and navigating a path through the BNC jungle.” Language Learning and Technology
5 (3): 37-
Lim, J. & M. Hwa (2006). Method sections of management research articles: A pedagogically
motivated qualitative study. English for Specific Purposes 25: 282-
Magnet, A. & D. Carnet (2006). Letters to the editor: Still vigorous after all these
years? A presentation of the discursive and linguistic features of the genre. English
for Specific Purposes 25: 173-
McCarthy, M. & M. Handford (2004). “Invisible to us”: A preliminary corpus-
Meyer, C., F. (2002). English Corpus Linguistics. An Introduction. Cambridge: Cambridge University Press.
Mudraya, O. (2006). Engineering English: a lexical frequency instructional model.
English for Specific Purposes 25: 235-
Nelson, M. (2006). Semantic associations in Business English: A corpus-
Nesi, H. and S. Gardner (2006) " Variation in Disciplinary Culture: University Tutors'
Views on Assessed Writing Tasks". In: Kiely, R., Clibbon, G., Rea-
Partington, A. (1998). Patterns and Meanings. Using Corpora for English Language Research and Teaching. Amsterdam/Philadelphia: John Benjamins.
Pecorari, D. (2006). Visible and occluded citation features in postgraduate second-
Rowley-
Samraj, B. (2005). An exploration of a genre set: Research article abstracts and
introductions in two disciplines. English for Specific Purposes 24: 141-
Simpson, R. C. (2004). Stylistic features of academic speech: The role of formulaic
expressions. In U. Connor & T. A. Upton (Eds.). Discourse in the Professions. Perspectives
from Corpus Linguistics, 37-
Sinclair, J. (1991). Corpus, Concordance, Collocation. Oxford: Oxford University Press.
Sinclair, J. M. (1996). “The search for units of meaning”. Textus 9 (1): 75-
Sinclair, J. M. (ed.) (2001). Collins Cobuild English Dictionary. London: Harper Collins. 3rd ed.
Swales. J. M. (1996). “Occluded genres in the academy”. In E. Ventola & A. Mauranen
(eds), Academic Writing, 45-
Swales, J. M. (2006). Corpus linguistics and English for Academic Purposes. In Elisabet
Arnó Macià, Antonia Soler Cervera & Carmen Rueda Ramos (Eds.), Information Technology
in Languages for Specific Purposes. Issues and Prospects, 19-
Velasco-
Webber, P. (2005). Interactive features in medical conference monologue. English
for Specific Purposes 24: 157-
© 2005-
Scripta Manent Vol. 3 (2)
» Contents
» P. A. Fuertes Olivera
Pedagogical Application of Specialized Corpora in ESP Teaching: the case of the UVaSTECorpus
» Y. Chen
Material Production for an EST Course: Coursebook Design for the English Training Programme for Architects and Civil Engineers
» Jenček
Angleško-
Recenzija
Previous Volumes