
Domov | O Zborniku | 10 let društva | SDUTSJ

Inter Alia 1
ISBN: 978-
ISSN:
Šarolta Godnič Vičič
Potentials and Challenges of ESP Learner Corpora: The Case of Modal Auxiliaries in Slovene ESP Learners' Written Interlanguage
ABSTRACT
A corpus-
Keywords: interlanguage, overuse errors, modal auxiliaries, ESP learner corpora.
Introduction
Research into second language acquisition (SLA) has shown that interlanguage -
The advent of computer learner corpus research in the late 1980s caused an upsurge
of interest in contrastive and interlanguage studies. Most studies based on learner
corpora, however, tend to use contrastive interlanguage analysis, which involves
either comparisons between native and non-
Corpus-
Corpus-
Contrastive learner corpus research is not without its problems. Although learner
corpora are not rare (an excellent review is provided by Pravec [2002]), the larger
corpora are more readily available only for the more widespread languages. There
are still problems with availability of suitable text retrieval software tools; what
is more, there is also a serious lack of certain types of corpora: spoken, longitudinal
and error tagged corpora, as well as learner corpora covering the field of languages
for specific purposes (Granger 2004; Myles 2005). There is also quite a wide agreement
that corpus-
This paper's aims are thus twofold: to determine whether small ESP learner corpora can assist ESP teachers in assessing the state of their students' interlanguage, and whether the existing resources are sufficient and accessible enough for such an analysis. To this purpose, a small corpus of student essays has been built and analysed by using a contrastive approach. Function words were selected for the analysis due to the fact that these words are members of closed systems, they are frequent, they occur in any text regardless of its topic or field, and they signal relationships between lexical words and larger units of language (Biber et al. 1999). What is more, past research shows that they are useful in approaching large mass of data. Finally, learners tend to meet them quite early in the foreign language acquisition process, therefore examples of functional words as actually used by learners can provide valuable information on the state of their interlanguage.
Although function words belong to a closed class, analysing them all would be beyond the scope of a single paper. Modal auxiliaries were selected for further analysis for two reasons. They are relatively well researched and learners’ use of modal auxiliaries have also been documented (Aijmer 2002; Neff et al. 2003; Neff et al. 2004), which would allow for a comparison with the ESP learner corpus data. Relevant research on modal auxiliaries will be reviewed and the corpus of learner essays will be described. Next, based on word frequency data and keyword analysis, the learners' overuse errors will be studied. Finally, relevant implications of the findings will be discussed.
2. Modal auxiliaries and learners
Biber et al. (1999) distinguish central modal auxiliary verbs (can, could, may, might,
shall, should, will, would and must) from marginal auxiliary verbs (need to, ought
to, dare to, used to) and semi modals (fixed idiomatic phrases with functions similar
to those of modals such as [had] better, have [got] to, be supposed to, etc.). They
also group central modals into pairs to distinguish past time and non-
a) permission/possibility/ability: can, could, may, might
b) obligation/necessity: must, should, (had) better, have (got) to, need to, ought to, be supposed to
c) volition/prediction: will, would, shall, be going to.
As regards the distribution of modals, large corpora show that semi-
Research into learner’s use of modals comprises both SLA and contrastive approaches.
Bardovi-
Studies in the contrastive tradition have found that advanced learners tend to overuse modal auxiliaries, yet the values for the individual modal auxiliaries vary according to learners' L1 (Milton and Hyland 1996; Aijmer 2002; Neff et al. 2003; Neff et al. 2004). Chinese learners use will and may twice as often as native speakers: they use will for confident predictions and may for denoting possibility (Milton and Hyland 1996). Swedish learners overuse will, must, have to, should and might; Aijmer (2002) suggests that learners’ overuse of will might be due to transfer of conversational uses to argumentative genres and that this could be a sign of learners’ inability to distinguish informal spoken and formal written forms. She also suggests that learners overuse must to sound more persuasive. Neff et al. (2003) noted overuse of can by Dutch, French, German, Italian and Spanish learners, with the Italian and Spanish learners showing the highest frequencies. Spanish learners’ overuse of can was attributed to transfer from learners’ native language and the inclusive writer stance, which is typical of Spanish speakers (the latter by Neff et al. 2004).
Attention to ESP learner corpora has been limited to the fields of business English (Connor, Precht & Upton 2002) and academic English (e.g., Flowerdew 1998; Gilquin, Granger & Paquot 2007). To my knowledge, learner corpora in the field of English for tourism purposes are nonexistent, and there is only one learner corpus of materials written by Slovene students: the corpus of Croatian interlanguage by Balažic Bulc (2005), which focuses on learners' use of connectors.
3. Methodology
3.1 The learner corpus
The Tourism Students' Essay (TSE) corpus is an ad hoc non-
The students were between 19 and 21 years of age and they had all learnt English for 9 years. As the essays were not intended for corpus data, specific data on the usual parameters of learner corpora (opportunities for learning English out of the educational system, mother tongue, other foreign languages spoken, etc.) were not elicited, however, students gave their written consent for including their essays in this corpus during the following academic year. The students’ foreign language competence was not tested with a reliable instrument. Based on my teaching experience I would say that most students’ English was at levels B1 and B2 of the Common European Framework. However, this assessment should be taken as tentative, especially since students’ individual skill levels tend to vary from skill to skill.
The essays are between 1600 and 2000 words long, which exceeds the length of essays included in other learner corpora. As a genre, the essays are not of a clear type: they range from clearly descriptive to more argumentative styles. The essay topic was chosen by the student. Topics such as tourism types, travel trends, groups of travellers, safety issues, mode of travel, etc., prevail.
3.2 The target language corpora
For a contrastive analysis, a target language corpus is also required. However, finding a suitable target language corpus turned out to be an impossible task. The Louvain Corpus of Native English Essays (LOCNESS), which is usually used as a reference corpus in such comparisons (e.g., Aijmer 2002; Neff et al. 2003; Neff et al. 2004), is not entirely appropriate: the essays are all argumentative and they cover topics that are not related to tourism, factors which may slightly distort the comparison (Biber 1988; Dagneaux 1995 and Hinkel 1995, both cited in Aijmer 2002).
To compensate for a lack of suitable target language corpus, the TSE corpus was compared to three target language corpora (Table 1):
· the Travel Supplement (TrS) corpus, an ad hoc corpus of travel articles from British and American newspapers that was built specially for this analysis;
· the written component of the British National Corpus (BNC Written);
· the spoken component of the British National Corpus (BNC Spoken).
The comparison with the TrS corpus guaranteed topic correspondence at least to a certain degree and the comparison with the BNC’s written component tackled the medium (i.e., written language). The spoken component of the BNC was also used for comparison since past research suggests that students’ interlanguage may be closer to the informal registers of spoken language (Aijmer 2002).
The analysis was performed with WordSmith Tools 3.0. using word frequency analysis and key word analysis. Individual words were further investigated with the help of WordSmith’s concordancer.
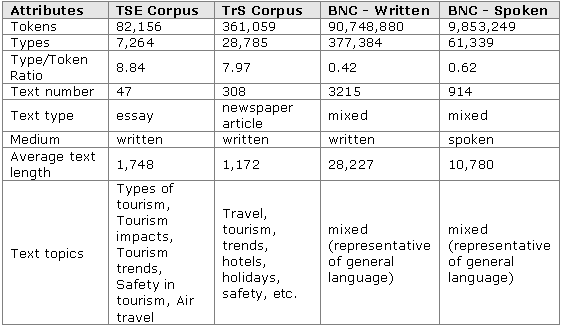
Table 1: Corpora attributes
4. Results
The word frequency analysis of the four corpora showed variation even among the first 10 words (see Table 2 below). The learner corpus exhibited distinct underuse of articles and distinct overuse of and, that, and the present forms of the verb be. The majority of the first 50 words in written corpora are typically function words. However, of all the three corpora, lexical words were most frequent in the TSE corpus.
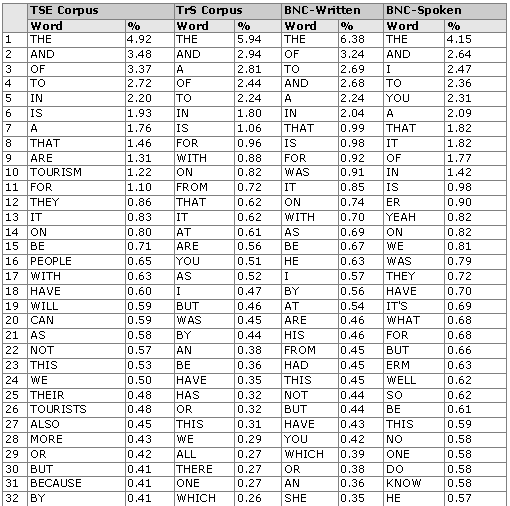
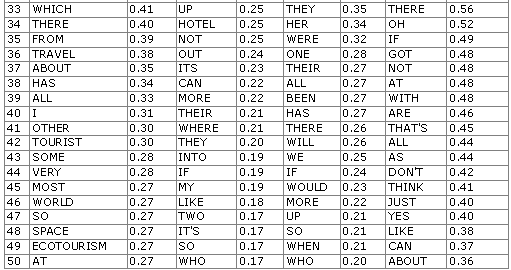
Table 2: The 50 most frequent words in the four corpora
Several small corpora were then built comprising travel articles from the TrS corpus of the same size as the TSE corpus to determine whether corpus size pushed lexical words up among the 50 most frequent words. However, there were never more than one or two lexical words among the first 50 words in these small corpora. Therefore, it was concluded that this phenomenon is probably caused by the limited lexical resources of the students.
In her study, Aijmer (2002) elicited only the following modal words: will, can, would, could, must, have (got) to, should, may, might, ought to and shall. Have (got) to was not included in this study since it was impossible to determine whether the author included has to, has got to or had to in her figures for this modal or not. Table 3 lists the frequencies of the modals in the TSE corpus and the three reference corpora, and Table 4 shows whether the differences between them are statistically significant.
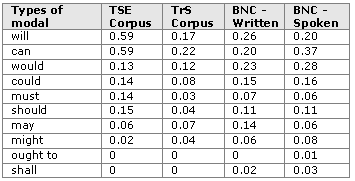
Table 3: Modal auxiliaries across the selected corpora in percentages
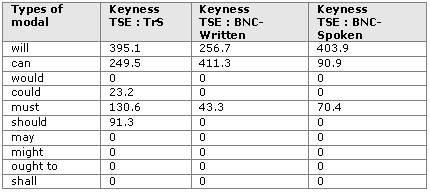
Table 4: Keyness of the modals in TSE Corpus vs. TrS Corpus, TSE Corpus vs. BNC-
Learners’ overuse of will, can and must was statistically significant in all three
comparisons. However, please note that their keyness -
The situation was quite different in the case of can. The difference was most significant
when the TSE corpus was compared with the written component of the BNC while the
comparison with the spoken component of the same corpus assigned much lesser significance
to this modal’s overuse. The discrepancy in the values suggests that it is possible
to say that the use of can signals a closer resemblance to the typical uses of this
modal in spoken language as suggested by Biber et al. (1999) or Aijmer (2002). This,
however, does not mean that other factors are not at play. The difference in the
frequency of can in the TSE corpus and the BNC-
Will, can and must are central modal auxiliary verbs (Biber et al. 1999) and actually
cover all three categories of meaning expressed by modals: can belongs to the permission/possibility/
ability group, must to the obligation/necessity group and will to the volition/prediction
group. Considering that these three modals are also those that learners of English
acquire first (at least in the Slovene educational system), their overuse may be
due to developmental reasons, which is in line with Bardovi-
There is another acquisitional factor to be considered: learners’ literacy development. It is well known that first year college students’ literacy skills are not yet fully developed in their native language. Figueredo (2006) shows that proficiency in literacy skills in the learners’ mother tongue can affect spelling in a foreign language. But does the development of literacy skills affect native speakers’ use of modals? To find it out, the frequencies of the three modals were looked up in the school essay and university essay components of the BNC.

Table 5: Modal verbs per million words in TSE, the school essay and the university essay components of the BNC
The data (Table 5 above) show significant differences in native speakers’ use of the three modals. Whereas frequencies of will and must show a falling trend, frequencies of can increase in the university essays. Whether these changes are due to higher literacy levels of native speakers, different topics, differences within the genre of the essay or all of these is impossible to tell as the BNC documentation (Burnard 2000) does not provide sufficient information.
When frequencies of the three modals in the university essay component of the BNC are compared to the Louvain Corpus of Native English Essays (LOCNESS), they show a discrepancy we cannot account for. Nevertheless, we can establish that the data in the essay components of the BNC seem to suggest that proficiency in literacy skills in one’s native language may affect the use of the three modal auxiliaries. Therefore, it seems possible that Slovene learners' proficiency levels of literacy in their L1 may affect their use of modals in both Slovene and in English. Based on the present data set, however, it is impossible to determine the nature of this transfer. For that, further research in this area would be required.
The issue of transfer from learners’ L1 must be addressed separately from the issue of literacy skills. Is the overuse of these three modals typical only of Slovene learners’ interlanguage? To determine this, frequencies of the modals in the TSE corpus were matched against frequencies of modal auxiliaries in the Swedish component of the International Corpus of Learner English (SWICL) and those in LOCNESS (Table 6 below).
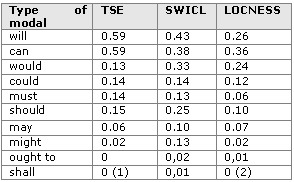
Table 6: Modal auxiliaries in TSE, SWICL and LOCNESS (Source: Aijmer 2002)
When the frequencies of will, can and must in the two learner corpora are compared to the LOCNESS frequency data, a distinct overuse can be observed. Will and can are overused by Slovene learners of English even more than by Swedish learners. Must, on the other hand, shows a similar frequency in both learner corpora. Therefore, the data seem to be in line with Aijmer (2002), who suggests that modals tend to be overused by learners of English but acknowledges that there are differences in the overuse of individual modals as well as in the degrees of overuse.
Finally, the issue of topical and general features should be addressed. If we regard the TrS corpus as a representative corpus of articles on travel, then the comparison with the newspaper component of the BNC could perhaps highlight differences which are due to topic or discipline. The discrepancy between the frequencies of the modals is statistically significant in most cases (Table 7). Especially significant are the lower values of will, would, could, and should in the TrS corpus. Can, on the other hand, is significantly overused in travel articles, which could suggest that the topics students write about in their essays may require them to use this modal more often.
Table 7: Modal auxiliaries compared: the TS Corpus and the Newspaper component of
the BNC-
Based on frequency data of modal auxiliaries it is impossible to determine the discourse and pragmatic reasons that lead to the above figures in travel articles. A detailed study would be needed if materials were to be informed by this discrepancy.
5. Conclusions
The first aim of this paper was to establish whether small ESP learner corpora can
provide important insights into ESP students' interlanguage. Focusing on the use
of modal auxiliaries in the interlanguage of Slovene students of tourism, we have
found that students significantly overuse will, can and must. However, providing
a clear-
First of all, developmental factors may play an important role in the overuse of
the three modals. As Bardovi-
On the other hand, as the comparison of the school and university essay components of the BNC has shown, literacy skills, too, undergo a developmental process that affects the use of modals by native speakers. However, how far the students' literacy skills in Slovene and their literacy skills in English affect their overuse of will, can and must could not be determined due to a lack of data on literacy acquisition in Slovene as well as a lack of data on modals in Slovene learners' interlanguage at various proficiency levels in English.
However, transfer of literacy skills is only one part of the story. Research has
shown that learners' L1 can affect which modals are overused and which not. Italian,
Spanish, French, Dutch, German, Chinese and Slovene learners overuse can but not
the Swedish or the Polish. The use of will or must shows a different picture across
these learner groups. Although we can establish that the differences are probably
due to transfer from learners' L1, what exactly in learners' L1 is the cause of this
transfer is impossible to determine without detailed analysis of their L1 -
As regards the text topic, it has been established that it affects the distribution of modal auxiliaries: most of them (will, would, could, should) are significantly underused in travel articles with the notable exception of can, which seems to be significantly overused in travel articles. Nevertheless, it would be impossible to assign students' overuse of can to a topical effect alone as such an effect would need to be accompanied by an underuse of will, must, should and could, which is not the case in the TSE corpus (see Table 4). All in all, the topic of the essays may affect learners' use of the three modals but to determine the nuances of this effect further analysis would be necessary.
Clearly, a definite explanation for the Slovene learners’ overuse of will, can and must cannot be provided. Nevertheless, certain pedagogical implications of these findings can be drawn for this particular group of students. First of all, learners’ awareness regarding their overuse of modals should be raised and contrasted with correct native speaker use. Then, lesser used modal auxiliaries and semi modals should be revised or introduced and practised. Such exercises could be especially beneficial because native language transfer seems to be working in combination with language acquisitional processes in this particular case and this may cause persistence in students' overuse errors. Finally, the teaching materials should be assessed and, if necessary, additional remedial exercises should be provided especially for the less frequently used means of conveying modality.
That brings us to the second aim of this paper: the assessment of existing resources that could assist ESP teachers in using learner corpora as a teaching resource. Firstly, building a learner corpus from texts written by students is simple if the texts are submitted in electronic form. However, finding suitable target language corpora is not as straightforward even when the target language is English. Learner corpora tend to be limited to advanced levels of English, written by students of English linguistics and comprising argumentative essays. As such they may not be a perfect match for interlanguage comparisons that could assist in highlighting L1 transfer. Furthermore, free access is allowed only to the Swedish and Polish components of the International Corpus of Learner English.
If we wanted to follow Altenberg's (2002) recommendation on comparing learner corpora
with comparable corpora in learners' L1, difficulties would only persist. While FIDA,
the Slovene national corpus, for example, is not freely available, FidaPlus is; however,
they do not seem to include school or university essays. Furthermore, the online
search facility, although helpful for simple word search, does not easily lend itself
to queries on frequencies and comparisons across genres as does for example the online
search facility of the BYU-
Although ESP for first year students does not contain language that is highly discipline specific, topical specifics of the language still affect both the textual intake of learners and the texts they produce. Therefore, a comparison of the learner corpus with a corpus of relevant discipline specific texts is recommended. Since such corpora are usually not widely available, building such a corpus has to be planned and performed by the ESP teacher. A discipline specific corpus would also be useful for the ESP teacher in the process of material design. Therefore, building a discipline specific corpus is only to be recommended.
Finally, this analysis would have also benefited from non-
1 How far they met this requirement is difficult to determine.
2 Key words are calculated by comparing frequencies of each word type in one corpus with the frequencies of the same word type in a larger reference corpus. If the difference in a word’s frequency in the two corpora is found to be statistically significant, the word will qualify as a key word (Scott 1999).
3 The difference between the two components of the BNC was calculated by using log-
4. LL -
References
Aijmer, K. (2002). Modality in advanced Swedish learners’ written interlanguage.
In S. Granger, J. Hung & S. Petch-
Altenberg, B. (2002). Using bilingual corpus evidence in learner corpus research.
In S. Granger, J. Hung & S. Petch-
Balažic Bulc, T. (2005). Connectors in students' academic writing in two closely
related languages (On the case of Slovene and Croatian language). Proceedings from
the Corpus Linguistics Conference Series. 1(1), ISSN 1747-
Bardovi-
Biber, D., Johansson, S., Leech, G., Conrad, S. & Finegan, E. (1999). Longman Grammar
of Spoken and Written English. Harlow: Longman -
Bley-
Burnard, L. 2000. Reference Guide to the British National corpus (World Edition). University of Oxford. Retrieved November 25, 2006, from http://www.natcorp.ox.ac.uk/docs/userManual/.
Cobb, T. (2003). Analyzing Late Interlanguage with Learner Corpora: Québec Replications
of Three European Studies. Canadian Modern Language Review/ La Revue canadienne des
langues vivantes, 59(3), 393-
deCock, S., Granger, S., Leech, G. & McEnery, T. (1998). An Automated Approach to
the Phrasicon of EFL Learners. In S. Granger (Ed.), Learner English on Computer (pp.
67-
Ellis, R. (1994). The Study of Second Language Acquisition. Oxford: Oxford University Press.
Figueredo, L. (2006). Using the known to chart the unknown: a review of first-
Flowerdew, L. (1998). Integrating ‘Expert’ and ‘Interlanguage’ Computer Corpora Findings
on Causality: Discoveries for Teachers and Students. English for Specific Purposes,
17(4), 329-
Flowerdew, L. (2002). The exploitation of small learner corpora in EAP materials design. In M. Ghadessy, A. Henry & R. L. Roseberry (Eds.), Small Corpus Studies and ELT: Theory and Practice. Amsterdam/Philadelphia: John Benjamins.
Gilquin G., Granger S. & Paquot M. (2007). Learner corpora: the missing link in EAP
pedagogy. Journal of English for Academic Purposes, 6(4), 319-
Granger, S. (2002). A bird's-
Granger, S. (2003). The Corpus Approach: A Common Way Forward for Contrastive Linguistics
and Translation Studies? In Granger S., Lerot J. and Petch-
Granger, S. (2004). Computer Learner Corpus Research: Current Status and Future Prospects.
In U. Connor & T. Upton (Eds.), Applied Corpus Linguistics. Amsterdam -
Han, Z. & Selinker, L. (1999). Error resistance: towards an empirical pedagogy. Language
Teaching Research, 3 (3), 248-
Meunier, F. (2002). The pedagogical value of native and learner corpora in EFL grammar
teaching. In S. Granger, J. Lerot & S. Petch-
Milton, J.C. P. and Hyland, K. (1996). Assertions in students’ academic essays: a
comparison of English NS and NNS student writers. Language analysis, description
and pedagogy. Proceedings of international conference organized by Language Centre,
HKUST (1996). HKUST, 1999 (pp. 47-
Myles, F. (2005). Interlanguage corpora and second language acquisition research.
Second Language Research, 21(4), 373-
Neff, J., Dafouz, E., Herrera, H., Martinez, F., Rica, J., Diez, M., et al. (2003).
Contrasting Learner corpora: the use of modal and reporting verbs in the expression
of writer stance. In S. Granger & S. Petch-
Neff, J., Ballesteros, F., Dafouz, E., Martinez, F. and Rica, J. (2004). Formulating
Writer Stance: A Contrastive study of EFL Learner Corpora. In U. Connor & T. Upton
(Eds.), Applied Corpus Linguistics. Amsterdam -
Nesselhauf, N. (2004). Learner corpora and their potential for language teaching. In J. Sinclair (Ed.), How to Use Corpora in Language Teaching. Amsterdam/Philadelphia: John Benjamins.
Nesselhauf, N. (2005). Collocations in a Learner Corpus. Amsterdam/Philadelphia: John Benjamins.
Petch-
Pravec, N. A. (2002). Survey of learner corpora. ICAME Journal, 26, 81-
Rigbom, H. (1998). Vocabulary frequencies in advanced learner English: A cross-
Scott, M. (1998). WordSmith Tools. Version 3.0. Oxford: Oxford University Press.
Selinker, L. 1972. Interlanguage. International Review of Applied Linguistics in
Language Teaching, 10 (3), 209-
Thompson, P. 2002. Modal Verbs in Academic Writing. In B. Ketteman & G. Marko (Eds.),
Teaching and Learning by Doing Corpus Analysis. Amsterdam -
|
Type of modal |
TrS Corpus |
BNC - |
LL |
|
will |
1,651 |
3,922 |
- |
|
can |
2,243 |
1,597 |
+109.19 |
|
would |
1,163 |
2,394 |
- |
|
could |
767 |
1,537 |
- |
|
must |
288 |
458 |
- |
|
should |
429 |
947 |
- |
|
may |
704 |
848 |
- |
|
might |
416 |
381 |
|
|
ought to |
17 |
22 |
|
|
shall |
6 |
41 |
- |
(CC) SDUTSJ 2008. Zbirka Inter Alia je objavljena pod licenco Creative Commons
Priznanje avtorstva-